Local Models and the Inference Subsidization Bubble
Is it possible to get Cursor-like functionality using local models running on a modest machine? See what the process has taught me about the sustainability of frontier models and the inference subsidization bubble.
Recent news about the U.S. Department of Defense's relationship with both Anthropic and OpenAI has opened many people's eyes to the kind of LLM use cases that the world's second largest employer is working towards; namely autonomous weaponry and mass surveillance of American citizens.
It‘s started to make me wonder: is it possible to use AI tools for software development without supporting OpenAI or Anthropic financially?
I set out to answer this question with a small experiment. The aim was to configure a fully local LLM development environment that meets the following criteria:
- Cursor/GitHub CoPilot-like functionality using a local LLM
- Running on reasonable consumer hardware not specialized for AI (I used a MacBook Air M4)
- In one shot: build a simple professional website based on the text of my resume with one piece of functionality: pull an updated summary of the most recent 3 blog posts from this blog and display them
Coding with Local Models: Dev Log
Full disclosure, I used ChatGPT and GitHub Copilot to help set up local coding models, find current tooling options, and as you will see; write a self-healing tool proxy for Ollama. This may seem contradictory, but the spirit of the experiment was to determine whether local models are usable for development of an isolated test prompt. ChatGPT and GitHub Copilot helped me to get the experiment up and running quickly.
There are two main decisions to running your own models locally: which model to choose, and which tools to use. There are some great tools out there for local development, here's a summary of what I tried and the results:
- Cline - This is a VS Code add-in that's supposed to add agentic behavior, but it does warn users that smaller/local models may not be capable enough. I tried this tool, but ran into ask_followup_question loops that blocked me from proceeding.
- Zed - This is a local VS Code-like editor. I was able to get chat to work, but wasn't able to get it to modify any files.
- Continue - Another VS Code add-in that I had a little bit more success with. It's got a lot of configuration options, and acted more like Cursor than the other options. I decided to keep iterating using Continue because I was able to get a little bit farther with it than the other tools. As an added benefit, it's open source.
Success or failure with any of these tools is almost entirely dependent on the strength of the model you're using, and it's not the fault of any of the above options that I struggled to get them to work. And there was a pattern to their failure modes: most models that can run on a MacBook Air M4 are not good at calling tools. Tools are how an LLM can perform external actions, such as reading and writing files, or accessing the internet.
When choosing a model, I started with the best available models for coding that would run on my MacBook. I tried Qwen2.5-Coder (7B/14B) and DeepSeek-Coder running in Ollama. Both were decent at generating code, but weren't able to call tools.
I thought maybe pushing the limits of my machine would allow me to use a model that can more reliably call tools, so next I tried Qwen3-coder:30b, which gave great output, but completely hung my machine, and still wasn't able to make tool calls reliably.
Tool usage ended up being my biggest hurdle to local agentic coding. The challenge is that output needs to be structured in the correct way, or Continue (or other agentic tooling) can't interact with files and other systems on the LLM's behalf. Some of these models flat-out did not know that tools existed, and just returned code to the chat window, others knew about tools and hallucinated JSON formatted output that did nothing.
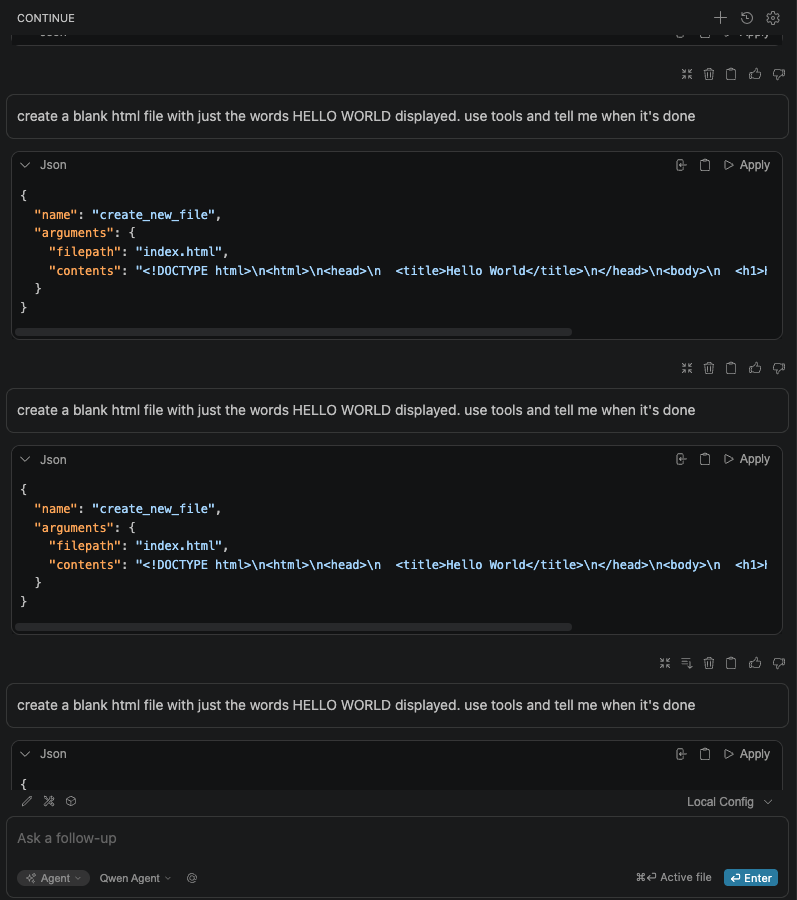
I set the project aside for a few weeks, and when I returned to it, 2 things had happened: Continue had improved support for tools, and a new model: Qwen3.5-9b with tool support was released. This model worked out of the box to create a simple "Hello, World!" html file on my MacBook.
These results were encouraging, but a nuance that I didn't understand would be a factor is that the more code you ask a smaller model to generate, the less accurate the tool calls are. When I asked it to generate my professional site, it would generate correct HMTL, but then would call the create_file instead of create_new_file which would cause it to fail after taking minutes to generate the HTML content. The model's ability to get the syntax correct seemed to be dependent on the amount of context I asked it to hold. I found the fact that it forgot details when overwhelmed to be extremely relatable.
The OLlama Proxy
While this was happening, I had pretty much zero visibility into what was going on behind the scenes. I needed some help debugging these issues, so I asked ChatGPT to create a proxy in Python to sit between Continue and Ollama to log requests and responses in real time. This turned out to be super helpful, because I could see exactly how the requests were failing.
It was frustrating that I was so close to a working agentic local model that was only failing due to typos and malformed commands. This is where the proxy became an invaluable tool. I moved to GitHub CoPilot and added some functionality to catch these small errors and fix the tool calls before they got back to Continue.
After this change, the model started working agentically and producing acceptable results about 5% of the time. I added some more functionality to the proxy to make tool calls more robustly self-healing and was able to get the hit rate up quite a bit, but most of the time it would generate a sparse website and crucially the blog feed never worked. The model would assume that my blog was using a certain technology (WordPress; but I use Ghost) so the post summaries wouldn't load.
LLMs can get really stuck on their assumptions, so I added a step to the proxy that asks the model to review the output before telling Continue that it's complete. The model immediately started lying to me and feeding me lists with emoji checkboxes without actually checking anything. My final review prompt ended up asking to check and verify the generated results against the user input before returning.
With the new verification pass, the model would navigate to the website and reason methods of pulling the blog posts for my specific blog instead of assuming WordPress. This resulted in the model successfully completing the task with the blog functionality about half of the time.
You can try the open source code for the proxy yourself here.
Some Surprising Results
At this point, I should mention that all of the successful runs of my pre-prepared prompt on local models took 3-5 hours to generate. I fully expected it to take a long time, that was part of the impetus behind the self-healing nature of the proxy: if I can set it to a task and come back later to working code, I could come up with a reasonable workflow.
However, quality-wise, the frontier models are an order of magnitude better and faster. I tried the exact same prompt with GPT 5.4 and Sonnet 4.6. Both were able to one-shot all of the requirements, including the live blog feed. The results from the frontier models were more stylish and better looking (though reasonable minds may disagree.) Crucially, both one-shots completed in under 10 minutes; with GPT 5.4 being slightly faster.
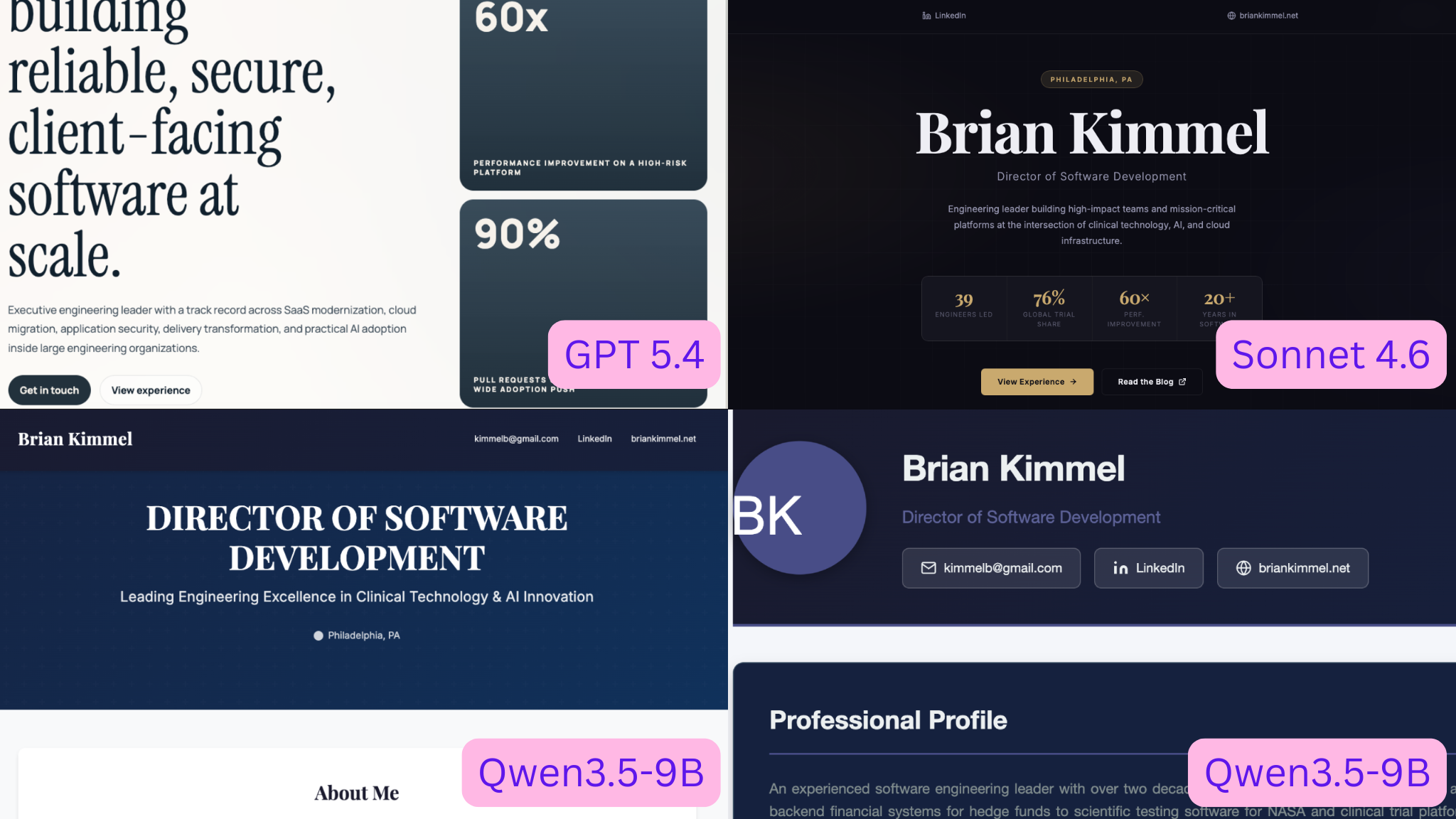
The Inference Subsidization Bubble and the Future of Frontier Models
The difference between using a local model that runs on my machine vs. a frontier model via a $10/mo subscription to GitHub Copilot (or $20/mo for Cursor,) was so stark that it really made me question how OpenAI and Anthropic are able to provide the current level of value at so little cost to the consumer.
Back of the Envelope Math
To answer that question, we can unscientifically extrapolate some information from my experiment, throw in some estimates, and come up with a comparison between what the frontier models cost a consumer and what it would cost to get the same result running open models on consumer compute.
Based on what I was able to get working with Qwen2.5-9B running locally, an initial working prototype of my test prompt was taking about 3 hours to complete. Implementation of the live blog fetching functionality was hit-or miss, so I would add another hour for iterating on the task to come up with a functional but ugly result. Then I would conservatively estimate design iteration at another 3 hours, though I am a bit skeptical that these smaller general models have any visual design capabilities at all.
The total time spent to fully implement my prompt, then, would be roughly 10 hours. I didn't notice the battery on my laptop drain particularly quickly while running inference, which matches with some other anecdotal reports. There aren't any good references for power draw for a MacBook Air M4 during heavy load, but estimates put the number between 20W and 65W. Erring on the side of lower-cost for this comparison, let's use 20W.
According to ElectricRates.org, my electricity provider’s rates are around 20¢/kWh all-in, so:
.02kW * 10 hours * $.20/kWh = 4¢Therefore, the electricity cost to complete this task using local LLMs was 4¢, which is incredibly low.
Electricity isn't the only cost, however, we also need to account for hardware depreciation. My MacBook was priced at around $1000 when I bought it. Most MacBooks have around a 5 - 8 year depreciation lifespan. Since running LLMs is heavy usage, let's use 5 years. Assuming that the depreciation numbers were based on surveys of people that use their computer 40 hours/week:
5 years * 52 * 40 hours/week = 10,400 hoursSo that $1000 hardware cost amortized over 10400 hours equates to about 9.6¢/hr. Multiplying that by 10 hours, it costs 96 cents in hardware depreciation to complete this task.
Adding $.96 to the $.04 electricity cost, we can estimate that it costs about $1 to complete this task using local LLMS.
To calculate the same cost for the frontier models, I ran the prompt against Claude Sonnet 4.6 in GitHub Copilot and compared my usage percentage before and after. I took this as a percentage of my monthly subscription fee to get the estimated cost to complete the same task. I did this estimation on the first of the month, so my starting percentage was low:
(percentage after inference - initial percentage) * subscription feeor
(.007 - .004) * $10 = 3¢The cost to complete this task using a frontier model was 3¢
These numbers are just estimates, but I think they can be helpful in drawing the following broad conclusions:
- Frontier models cost a tenth of the price of running your own hardware
- They complete tasks in 1-2% of the time, and;
- The results are much better and require less human oversight to get good outputs
And this is just for inference. Some reports show that OpenAI spends more than double it’s inference compute on R&D. That cost differential really raises questions about how OpenAI and Anthropic are providing these services so cheaply.
Wild Speculation and Unfounded Predictions
It's been widely reported and debated whether and how much Anthropic and OpenAI are subsidizing inference to drive adoption and win market share.
Given how much faster and more accurate their models are than what can reasonably be run locally, I'm convinced that these companies are selling inference at a loss. Even if cost were equivalent, their models are better at coding than open models. It's not possible at this time to match the productivity gain of frontier models without paying Anthropic or OpenAI.
If that's true, it could indicate that we're in an AI bubble and that the current state of access to frontier models is at risk of collapse or inflation. Both Anthropic and OpenAI are rushing for market share, using inference as a loss leader. What happens then, when the market is fully saturated? The cost of these models will creep up slowly over time. Small companies or independent engineers will only be able to afford the enshittified version of these tools and they won't be able to keep up.
It’s actually already starting to happen. While working in this experiment, Microsoft announced that GitHub Copilot is moving to usage-based billing.
Meanwhile, Even now, it's essentially impossible for an individual engineer to run their own models and keep their skills on par with the rest of the software engineering industry.
Therefore, it behooves engineering leaders and individual contributors to diversify their tool and model adoption. That means developing tools and features that are model agnostic, and building engineering practices that are tool agnostic. It's our only hope of avoiding a future AI duopoly.